Как работает "Бизнес Семантика"?
 В этой статье мы объясним, как именно работает связь информационных систем посредством сервера "Бизнес Семантика".
В этой статье мы объясним, как именно работает связь информационных систем посредством сервера "Бизнес Семантика".
Для примера возьмем случай объединения двух информационных систем. Пусть это будут два приложения, использующие базы данных MySQL и Oracle. Они должны обмениваться сведениями о клиентах и контактах (звонках, встречах) с ними. То есть, если клиент создан в одной из этих программ - он должен немедленно появиться в другой; если в свойства клиента в одной из программ будут внесены изменения, или он будет удален - то же самое должно произойти и в другой системе.
Все описываемые ниже действия по настройке обмена в процессе внедрения могут выполнить как специалисты заказчика, так и наши сотрудники! Итак, пройдем все шаги настройки обмена.
1. Составить онтологию
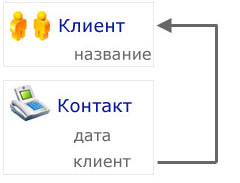 Для начала, необходимо составить онтологию, или описание всех видов объектов, информацией о которых будут обмениваться наши системы, и их свойств. В нашем примере, чтобы не усложнять схему, ограничимся простым набором. Пусть каждый клиент имеет только одно свойство - название. Контакт будет иметь два свойства: дату, когда он произошел, и клиента, с которым мы пообщались. Свойства "название" и "дата" будут представлять собой литералы, то есть некие фиксированные значения (строка, дата). Свойство "клиент" у контакта будет представлять собой ссылку на объект, определенный в этой же онтологии (Клиент). Конечно, на практике свойств у таких информационных объектов было бы намного больше, но все они создаются совершенно одинаковым образом.
Для начала, необходимо составить онтологию, или описание всех видов объектов, информацией о которых будут обмениваться наши системы, и их свойств. В нашем примере, чтобы не усложнять схему, ограничимся простым набором. Пусть каждый клиент имеет только одно свойство - название. Контакт будет иметь два свойства: дату, когда он произошел, и клиента, с которым мы пообщались. Свойства "название" и "дата" будут представлять собой литералы, то есть некие фиксированные значения (строка, дата). Свойство "клиент" у контакта будет представлять собой ссылку на объект, определенный в этой же онтологии (Клиент). Конечно, на практике свойств у таких информационных объектов было бы намного больше, но все они создаются совершенно одинаковым образом.
Онтологию нужно сохранить в виде файла формата RDFS (OWL). Сделать это можно при помощи любого хорошего редактора онтологий, или даже просто редактора XML. В ходе проекта по внедрению эту работу обычно выполняем мы, однако создавать онтологии или вносить в них изменения не так сложно, как может показаться. Для этого существует большое количество специальных программ. Некоторые из них, такие как TopBraid Composer, позволяют работать с иерархическим представлением онтологий. Другие, например FluentEditor от компании Cognitum, позволяют создавать онтологию путем ввода фраз на естественном языке. Есть и средства визуального моделирования онтологий OWL. Предлагаем вам посмотреть видеоролик, в котором требуемая в нашем примере онтология создается при помощи программы Fluent Editor.
Вы можете также посмотреть ролик о создании той же самой онтологии в TopBraid Composer.
В этом примере мы создали онтологию "с нуля", однако, конечно, можно использовать элементы любых готовых онтологий - например, Dublin Core. Можно работать и с онтологиями ISO 15926.
2. Настроить сервер
Теперь нужно установить и настроить сервер. Устанавливается он, как любое веб-приложение; процесс установки описан в документации. Когда сервер будет запущен - необходимо войти в веб-интерфейс, и загрузить онтологию. Затем нам необходимо создать учетные записи для обеих информационных систем - это также делается через веб-интерфейс управления сервером. Наконец, нужно задать права доступа систем - определить, какие виды объектов и их свойств сможет читать и записывать каждая система. Это делается путем расстановки галочек в веб-интерфейсе сервера.
3. Настроить клиентские модули
Перейдем к настройке клиентов (также они называются коннекторами). Это программные компоненты, которые отвечают за интеграцию, со стороны каждой из информационных систем. Если для наших информационных систем есть готовые коннекторы, особых проблем не возникнет: нужно будет установить их в соответствии с инструкцией, и сообщить им ту же онтологию, которую мы использовали для сервера (или ее части). Нужно установить соответствие между элементами онтологии и полями базы данных нашей информационной системы. Некоторые коннекторы позволяют сделать это при помощи визуального интерфейса, в некоторых - сопоставление прописывается в специальном массиве в программном коде. Для тех объектов и свойств схемы, которым нельзя однозначно сопоставить какие-либо элементы базы данных, придется определить специальные обработчики, и подключить их к коннектору при помощи простого программного интерфейса. Обработчики создаются на языке, естественном для данной программной среды.
Интеграция настроена! Как же происходит сам процесс обмена?
4. Передача информации об изменении данных
Как только в какой-либо информационной системе создается, изменяется или удаляется объект, сведения о котором интересны другой информационной системе - автоматически активируется фрагмент программного кода коннектора (это достигается при помощи инструментальных средств, которые предоставляет та программная среда, в которой работает коннектор). Коннектор собирает информацию об изменившемся объекте, возможно - о связанных с ним объектах, которые еще не передавались другой ИС, и отправляет все эти данные серверу. Сервер получает данные, временно размещает их в своей базе данных, и затем сообщает другой информационной системе.
5. Получение информации об изменившихся объектах
С определенной периодичностью (достаточно часто - скажем, каждые 20 секунд) каждая из клиентских информационных систем опрашивает сервер, с целью узнать, нет ли для нее подготовленных к передаче данных. Если такие данные обнаружены, сервер сообщит их клиенту. Задача клиента состоит в том, чтобы преобразовать полученные сведения в соответствии с имеющимися у него правилами, и поместить информацию в свою базу данных. Передача завершена! Информация достигла точки назначения.
В заключение, приведем схему взаимодействия сервера с двумя клиентами. Пусть один из них встроен в веб-ориентированную CRM-систему, а другой - в конфигурацию 1С.
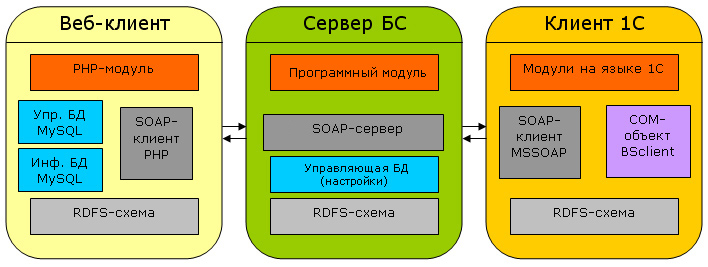
Конечно, тем, что описано в данной статье, алгоритмы работы "Бизнес Семантики" не исчерпываются: есть еще процессы восстановления целостности данных, механизмы отслеживания и автоматического восстановления после сбоев передачи, и многое другое.